
發布時間:2020-11-09 16:51:56
標簽:監控探頭如何識車牌
瀏覽(48214)
接上文
監控探頭如何識別你的車牌?四通搬家公司通俗講解人工智能(上)
隨著硬件和算法的突破以及大規模神經網絡的應用,使得全天候的車牌定位和識別不再成為問題,那么如何具體實現呢?
02
—
字符分割
將車牌提取出來以后,還要進行一次形態學處理和濾波器過濾,用來去除微小的干擾元素、粘連和噪點,圖像中非車牌字符的干擾越少,識別正確率就越高!
這時顏色對我們來說也沒有意義了,顏色并不會對字符識別有所幫助。因此我們用純粹的黑白圖像取代彩色的車牌圖像來簡化處理過程,這種圖像只包含純黑和純白,如果之前已經把干擾基本消除了的話,我們會得到一張非常清晰的車牌圖像,有字或邊框的地方為純白,無字的背景是黑色。

四通搬家貨車的車牌經過處理以后的圖像,比之前清晰很多了
現在,我們面臨一個問題,即分割出來的單字不能帶有邊框,否則會嚴重影響計算機的判斷。比如,如果數字1的上下都有橫線邊框,計算機可能會將其誤認為是字母Z。還有一些家用轎車的車牌外延有一圈不銹鋼邊框,這個邊框的寬度如果不去除的話也會對識別造成很大干擾。

有兩種方法來消除邊框。
,由于邊框是白色,所以從上到下,每一行逐個查看像素是黑還是白,如果發現一整行的像素全都是白色,則判斷這行一定是邊框。同理,從左至右,每一列逐個查看像素黑白,也能判斷出左右兩端的邊框位置。
第二種方法更簡單,由于攝像頭位置固定,如果我們能保證每次提取出來的車牌圖像尺寸基本一致的話,根據我國公布的車牌格式標準,把所有得到的車牌按比例直接剪裁掉一部分邊界區域就可以了。
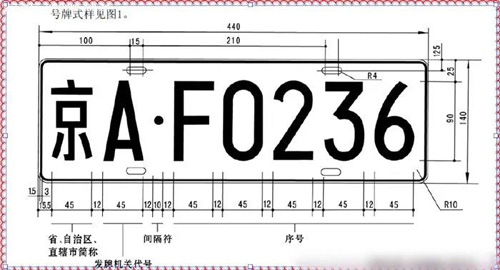
另外,上下的鉚釘可以通過統計整行像素的躍變次數來去除(因為鉚釘所在的行的像素變化肯定少于有文字部分的行)。

去除了邊框和鉚釘
現在,我們終于得到了一張完美的不含任何干擾因素的車牌,可以開始分割單個字符了。這時就無法按照格式尺寸來直接切割了,因為不能保證拍攝到的車牌圖像尺寸如此精確到能夠按照比例正好分割到字符間隙的位置。
我們需要借助投影法來確定分割位置。所謂投影,就是對一整行或者一整列的像素數求和。這里要用到列投影也就是垂直投影,即從左至右統計每一列的像素總數,然后畫出一張統計直方圖。

垂直投影展示了字符存在的7個區域,凡是有字符的地方就是有能量的(黃色),凡是不存在字符的列就是沒有能量的藍色
簡單地說,由于字符是白色,背景是黑色,那么車牌上字符之間的間隙就是白色像素數少的部分,通過上邊提到的的垂直投影就可以在直方圖上顯示出波峰和波谷,其中波谷也就是圖上藍色的能量的幾個位置,它們一定就是字符間隙,從這幾個位置下刀進行分割一定錯不了!這樣就可以分割出7個獨立的字符了。

03
—
字符識別
終于進入的識別模塊了!總得來說,單字的識別技術相對于車牌定位和字符分割來講是簡單的部分。
主要的字符識別方法有兩種:
模板匹配
深度神經網絡
模板匹配:常用的識別方法。通過建立已知的字符模板庫,再將需要識別的單個字符與模板庫的字符進行比較;也就是用待識別的字符與模板庫中的所有字符圖像逐一做減法,差異小的就是識別結果。這種方法速度快,但是在神經網絡成熟以后,模板匹配就顯現出了不夠精準的問題。例如,如果一幅在雨雪天氣中捕獲的不太清晰的車牌圖像,那么同為方塊字的結構類似的漢字間的差異可能并不大,這就會造成識別錯誤。
深度神經網絡:和車牌定位中提到的神經網絡是一個道理。將大量不同樣式的單個字符作為樣本,讓計算機通過神經網絡去學習和訓練,計算機就能具備分辨單個字符的能力。實際上,這樣的神經網絡被稱為分類器,也就是將待識別的字符自動歸類到計算機在訓練中學到的某一類型字符中。這種方法需要海量的各種情況下拍攝到的單個字符樣本,現在道路攝像頭用的識別模塊一般就是這種方法。在巨量訓練樣本的加持下,神經網絡具備對較模糊的漢字的精準識別能力。更關鍵的是,通過有針對性的訓練,神經網絡甚至能夠像人腦一樣對殘缺的字符進行一定程度上的推測。

用于神經網絡訓練的一小部分字符樣本

神經網絡通過學習能夠識別出目標字符
終,我們得到了正確的結果!前邊的內容看似很長,但隨著硬件的進步、普及和成本的下降,內置高性能處理芯片的監控探頭設備可以在不足半秒的時間內就完成上述所有的步驟。這些探頭無需將拍攝的照片傳回數據中心再處理,而是直接拍完就可以自我處理圖像并進行識別,準確率大于95%,通過4G或者有線網絡傳回識別結果就可以了,大大降低了交警數據中心的負荷。如果在不通網絡的地區,則探頭設備會將識別結果自動存儲在內置硬盤中,交警會定期去探頭所在地取回硬盤數據。

彩蛋
—
關于國外

歐洲的車牌自動識別起步很早,但是準確率卻不盡如人意。以德國為例,根據統計,德國黑森州、薩克森和巴伐利亞州在2016到2017年抓拍到的共150萬張違章車牌圖片中,自動識別正確的僅有3萬余張,錯誤率竟然高達驚人的98%,簡直令人噴飯!不過,歐盟境內各國不同的車牌書寫格式也是造成自動識別率低的一個原因。

德國道路卡口照片,左上角的識別結果將N4046識別成了N4346

由于未處理好鉚釘問題,將JK識別成了UK

識別結果漏掉了首字母H,仍是未處理好鉚釘造成的粘連問題。
其實,歐洲具備起步很早的光學字符識別技術(OCR),可能你在將紙上的文字掃描進入電腦并直接形成可編輯的電子文檔時用過這種技術。對于完全由字母和數字組成的歐洲車牌來講,借助一種基于類似水域分割和圖論的思想配合成熟的字母數字OCR模塊可以簡單高效地自動分割并識別字符。上述德國三個州發生的這種過高的錯誤率應該是由于部署了未經針對性訓練或者設置了不恰當閾值參數的監控設備所導致的。

OCR掃描筆可以快速將紙上文字錄入電腦

四通搬家保障
讓您放心搬家

爽約5倍賠
期詐3倍賠
亂收費2倍賠
 明碼標價
明碼標價
 損壞賠償
損壞賠償
 全國連鎖
全國連鎖
 一站式服務
一站式服務
 微信小程序
微信小程序



